一、华镇电子语音识别引擎
高识别率:华镇电子语音识别技术聚合核心算法、解码器核心以及先进的声学模型和语言模型训练方法。在各种领域和应用场景下都具有极高的可用性和实用性,使用户在广泛的领域中都可以利用语音识别服务来取代传统的键盘输入或者自动对语音数据进行分析、质检、索引等进一步操作。更高的自动化程度,意味着用户将以更低的成本享受更高质量更人性化的服务。
成熟性: 上海华镇在语音识别领域具有深厚的技术沉淀,以其高度识别性能和创新性在众多领域拥有相当多的成功案例,具有很高的成熟度。
技术保障:上海华镇坚实的综合实力、成熟的研发团队,都是用户得到稳定支持服务的有力保障。
二、语音识别基本原理
这里简单介绍一下语音识别的基本原理。下图是一个典型的语音识别的框架,其中有三个重要的组成部分:模型训练、前端语音处理、后端识别处理。
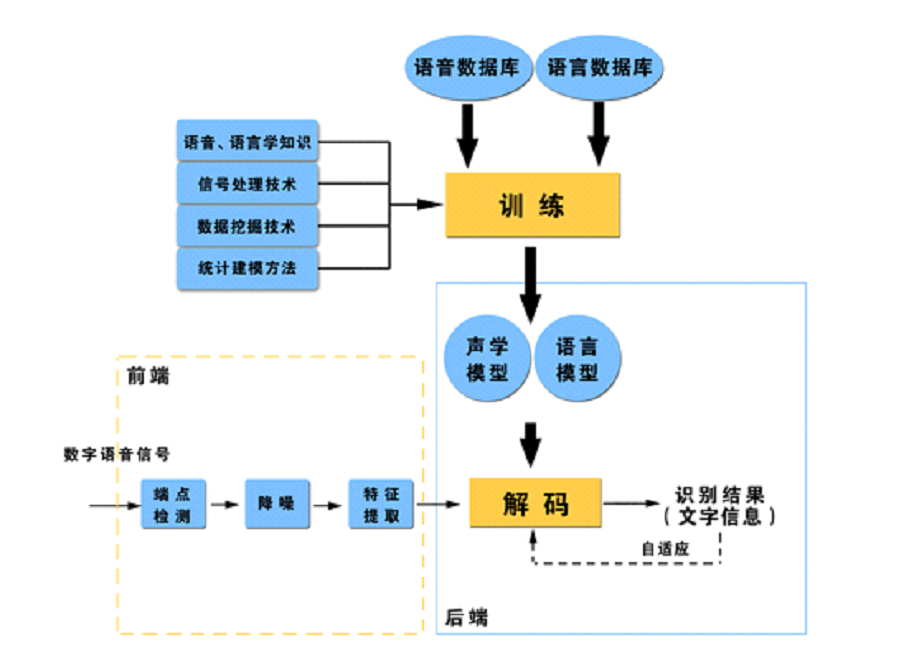
1、模型训练
语音识别系统的模型通常由声学模型和语言模型两部分组成,分别对应于从语音信号中抽取的特征到音节概率的计算和音节到字概率的计算。
目前声学模型的建模方法普遍采用DNN(深度神经网络)+ HMM(隐马尔可夫模型)的方法,对比前一代使用GMM(混合高斯模型)+HMM的方法,语音识别错误率下降了30%,是近20年来语音识别技术方面较快的进步。而在语言模型方面,目前通常采用统计语言模型的建模方法,其中N-Gram简单有效,被广泛使用。
为了适应不同年龄、不同地域、不同人群、不同信道、不同终端和不同噪声环境的应用环境,需要大量语音语料和文本语料来进行训练,才能有效提高识别率。随着互联网的快速发展,以及手机等移动终端的普及应用,目前可以从多个渠道获取大量文本或语音方面的语料,这为语音识别中的语言模型和声学模型的训练提供了丰富的资源,使得构建通用大规模语言模型和声学模型成为可能。
在语音识别中,训练数据的匹配和丰富性是推动系统性能提高的主要因素之一,但是语料的标注和分析需要长期的积累和沉淀,随着大数据时代的来临,大规模语料资源的积累将提到战略高度。
2、前端语音处理
前端语音处理指利用信号处理的方法对说话人语音进行check、降噪等预处理,以便得到适合识别引擎处理的语音。主要功能包括:
1) 端点检测
端点检测是对输入的音频流进行分析,将语音信号中的语音和非语音信号时段区分开来,准确地确定出语音信号的起始点。经过端点检测后,后续处理就可以只对语音信号进行,这对提高模型的精准度和识别正确率有重要作用。
2) 噪音消除
在实际应用中,背景噪声对于语音识别应用是一个现实的挑战,即便说话人处于安静的办公室环境,在电话语音通话过程中也难以避免会有一定的噪声。一个好的语音识别引擎需要具备有效的噪音消除能力,以适应用户在千差万别的环境中应用的要求。
3) 特征提取
声学特征的提取是一个信息大幅度压缩的过程,也对后面的模式分类器能否更好地进行模式划分起到重要的影响,因此,声学特征的提取与选择是语音识别的一个重要环节。目前常用的特征包括MFCC, PLP等。
3、后端识别处理
后端识别处理就是指利用训练好的“声学模型”和“语言模型”对提取到的特征向量进行识别(也称为“解码”),得到文字信息的过程。声学模型的主要目的是对应于语音特征到音节(或者音素)概率的计算,语言模型的主要目的是对应于音节到文字的概率的计算。而其中主要的解码器部分就是指对原始的语音特征进行声学模型打分和语言模型打分,并在此基础上得到更优的词模式序列的路径,此路径上对应的文本就是识别结果。
早期的基于语法树结构的解码器,设计较为复杂,并且在当前技术条件下,其速度已经碰到瓶颈,而目前大多主流的语音识别解码器已经采用基于有限状态机(WFST)的解码网络,该解码网络可以把语言模型、词典和声学共享音字集统一集成为一个大的解码网络,大大提高了解码的速度,也能够将解码过程和知识源分离。
4、后端识别处理
后端识别处理就是指利用训练好的“声学模型”和“语言模型”对提取到的特征向量进行识别(也称为“解码”),得到文字信息的过程。声学模型的主要目的是对应于语音特征到音节(或者音素)概率的计算,语言模型的主要目的是对应于音节到文字的概率的计算。而其中主要的解码器部分就是指对原始的语音特征进行声学模型打分和语言模型打分,并在此基础上得到更优的词模式序列的路径,此路径上对应的文本就是识别结果。
早期的基于语法树结构的解码器,设计较为复杂,并且在当前技术条件下,其速度已经碰到瓶颈,而目前大多主流的语音识别解码器已经采用基于有限状态机(WFST)的解码网络,该解码网络可以把语言模型、词典和声学共享音字集统一集成为一个大的解码网络,大大提高了解码的速度,也能够将解码过程和知识源分离。
 沪公网安备 31011502005748号
沪公网安备 31011502005748号 